僕のコーヒーの楽しみ方
みなさんはいつもどのようにコーヒーを楽しんでいますか? 僕は10年ほど前から、コーヒー豆を挽いてハンドドリップで淹れるのが日課になっています。 僕のコーヒーの楽しみ方を書かせていただきたいと思います。
ハンドドリップして水筒で持ち歩く
仕事の最中でも、外出先でも、いつでも美味しいコーヒーが飲みたいですよね。 なので僕は、朝にペーパードリップ3〜4杯分のコーヒーを淹れて水筒で持って出かけます。 3〜4杯分を一気に淹れると美味しく淹れやすいと思いますし、水筒に淹れておけば酸化しにくく美味しいままです。 ぬるくなってしまいますが、美味しいコーヒーはぬるくなっても美味しいと、僕は思っています。 (個人の感想です)
ペーパードリップは良いですよね。 色々試しましたが最も手軽で美味しいです。
僕が使用しているドリッパーは👇のフラワードリッパーです。
エスプレッソやカフェラテを手軽に楽しむ
エスプレッソ、美味しいですよね。 お砂糖をたっぷりいれて、くいっっと。 時間がなかったり、お腹がいっぱいでコーヒー1杯飲みきれない・・・けどコーヒーが飲みたい!という時に最適ですね。
エスプレッソを淹れて、ミルクを注いでカフェラテにするのも良いです。 僕は牛乳が大好きなんですが、カフェラテはもっと好きです。
家でエスプレッソを楽しみたいと思うと、なんだかんだで手間がかかってしまいます。 手軽に飲みたい!
そこで、うちでは Nespresso を使ってエスプレッソを手軽に楽しんでいます。
Nespresso を買うまでは、カプセルを使うタイプのコーヒーメーカーは美味しさもイマイチな印象がありましたし、1杯にかかるコストも自分でドリップするよりかかると思いますし、あまり良いイメージはありませんでした。
Nespresso は、コストはやはり割高とは思いますが、美味しいです。 なんと言っても美味しいエスプレッソやカフェラテを、気軽に楽しめるところが良いです!
手間をかけた美味しいコーヒーも良いですが、自宅で気軽にコーヒーを楽しみたいときはこれですね!
もっと手軽にコーヒー豆を楽しむ
次女が生まれる際に、妻と長女がお世話になるのでそのお礼と、僕も入り浸りになるので、ということで義実家に👇のコーヒーメーカーをプレゼントしました。
このコーヒーメーカーは、「マツコの知らない世界」のコーヒーメーカーの特集で、もっともイチオシのコーヒーメーカーとして紹介されていました。
豆を挽くところから自動で、ハンドドリップが苦手な方でも美味しいドリップコーヒーを楽しめます。
水を少なめにし、濃いめの設定でドリップしたものは、氷を足してアイスコーヒーとしても楽しめます。
まとめ
以上、駄文ですが僕のコーヒーの楽しみ方を紹介させていただきました。 お読みいただきありがとうございました。
Next.js メモ
本当にただのメモ
気づきとか意外なこととかをメモしていきます。
コンポーネント内で空白スペースをうまくいれるには
以下のように改行があったとしてもスペースなしになる。
Helloの後ろや <strong> の前にスペースを入れたくても prettier などで補正されてしまったりする。
return (
<div>
Hello
<strong>Hori-chan.</strong>
</div>
);

スペースを入れたい場合は以下のようにする。
return (
<div>
Hello{" "}
<strong>Hori-chan.</strong>
</div>
);

Static Generation か Server Side Rendering かはページごとに選べる
getStaticProps
- dev 起動時には request ごとにしか動かない
- build 時にはビルド時にしか動かない(何言ってる)
- getStaticKeys のフォールバックキーでより便利になる(なんのこっちゃ)
- Page でしか使用できない(単なるコンポーネントは無理)
Mac でのキーボード設定など
Mac でのキーボード設定
Mistel Barocco M770 の設定
- ディップスイッチ1 のみ ON
- マクロ等なし
システム環境設定
- システム環境設定
- キーボード
- キーボード
- キーのリピート → 最速
- リピート入力認識までの時間 → 最短
- 修飾キー
- USB-HID Keyboard (Barocco のこと)
- Ctrl と Command を入れ替える
- 内蔵キーボード(JIS配列)
- Caps Lock → Command (一番左下のキー)
- Ctrl → Caps Lock
- Command → Ctrl
- USB-HID Keyboard (Barocco のこと)
- ユーザ辞書
- 英字入力中にスペルを自動変換 → OFF
- 文頭大文字 → OFF
- スペースバー2回でピリオド → OFF
- 入力ソース
- 音声入力
- ショートカット → OFF
- キーボード
- キーボード
- Karabiner-Elements
- 無効にする・インストールしない
Rust Tips : バイナリプロジェクトにおける責任の分離
以下の記事から引用&和訳したものです。 大事なので、なんども読みたいので、載せました。
複数のタスクの責任をmain関数に割り当てるという組織上の問題は、多くのバイナリプロジェクトに共通しています。そのため、Rustコミュニティでは、バイナリプログラムのmainが大きくなり始めたときに、別々の関心事を分割するためのガイドラインとなるプロセスを開発しました。このプロセスは次のようなステップで構成されています。
- プログラムをmain.rsとlib.rsに分割し、プログラムのロジックをlib.rsに移動します。
- コマンドライン解析ロジックが小さいうちは、main.rs に残すことができます。
- コマンドライン解析ロジックが複雑になり始めたら、それを main.rs から抽出して lib.rs に移動します。
この処理の後、main関数に残る責任は以下のように限定されるべきです。
- コマンドライン解析ロジックを引数の値で呼び出すこと
- その他の設定を行う
- lib.rs内のrun関数の呼び出し
- runがエラーを返した場合のエラー処理
このパターンは、懸念事項を分離するためのものです。main.rsはプログラムの実行を処理し、lib.rsは手元のタスクのすべてのロジックを処理します。main関数を直接テストすることはできませんが、この構造であればプログラムのすべてのロジックをlib.rsの関数に移してテストすることができます。main.rsに残る唯一のコードは、それを読むことでその正しさを検証できるほど小さくなります。
僕のRust チートシート
自分のためのチートシートを作ります。 このチートシートを少しずつ育てていくことにする。
- コマンド
- 調べる
- サードパーティクレート
- 小技
- main 関数からは Ok / Err を返せる
- Resultが返る関数においてErrが返ったら即リターンする?構文
- Vec<i32>の合計値を求めようとして苦労した
- 整数同士で割り算するなら先に as f64 しておく
- 使用しない戻り値は_に代入する
- Mac でビルド成果物を実行する
- 標準ライブラリで最も一般的なスマートポインタ
- Rc::clone の使い所
- Interior mutability pattern(インテリアミュータビリティパターン)
- Rc と RefCell の合わせ技
- MPSC
- 連番のVecを作る
- スレッド間で値を安全に共有するためのAtomic Reference Counting, Arc.
- 等価比較する
- impl 内の fn の引数で self: Box<Self> になってるのなに
- パターンがマッチし続ける限りwhileループを実行することができる while let
- イテレータの中身をindexとともに取得したい時は enumerate() を使う
- Vec<u32>.iter().map(|n| *n++) のように n は dereference が必要?
- collect() を変数に格納せずに型指定する
- お手軽にコピーしたいときは
- テストで println! を標準出力する
- Rust の Vec をインデックス付きでループする方法
- JS でいうところの array.some
- Rust の補完が効かない問題
コマンド
| command | 説明 |
|---|---|
cargo new hello_world |
バイナリプロジェクトを作る |
cargo new --lib hello_world |
ライブラリプロジェクトを作る |
cargo search hello_world |
クレートのバージョンについて調べる |
調べる
| 知りたいこと | 参考URL |
|---|---|
| vecの使い方について | 公式ドキュメント |
| arc | TRPL |
サードパーティクレート
| クレート名 | 説明 | 参考URL |
|---|---|---|
| structopt | コマンドライン引数をいい感じに受け取る | MS Learn |
| chrono | 日付と時刻のデータを処理する | MS Learn |
| slice_group_by | vec内でグループを作る時に使うと便利。group-by は公式に実装される予定がある。 | docs.rs |
| serde | 型から Serialize と Deserialize の特性を派生できるようにするベース クレート | MS Learn |
| serde_json | Serialize と Deserialize の特性を、選択したファイル仕様形式である JSON に実装するクレート | MS Learn |
| home | ユーザーのオペレーティング システムによって異なるHOMEディレクトリを判断する | MS Learn |
| anyhow | 有用で適切なエラーをユーザーに表示できる | MS Learn |
小技
main 関数からは Ok / Err を返せる
fn main() -> Result<(), ()> { Ok(()) }
exeにコンパイルした場合、Ok(())をリターンすると実行結果は0となり、Err(())をリターンすると実行結果は1となる。
随所に出てくる不自然な() は、空のタプル。voidのようなものだろうか。
Resultが返る関数においてErrが返ったら即リターンする?構文
use std::error::Error; use std::fs::File; fn main() -> Result<(), Box<dyn Error>> { let f = File::open("hello.txt")?; Ok(()) }
Vec<i32>の合計値を求めようとして苦労した
fn sum(list: &Vec<i32>) -> i32 { list.iter().as_slice().iter().sum::<i32>() }
整数同士で割り算するなら先に as f64 しておく
fn mean(list: &Vec<i32>) -> f64 { list.iter().as_slice().iter().sum::<i32>() as f64 / list.len() as f64 }
使用しない戻り値は_に代入する
生真面目にlet result =みたいに書くと警告吐かれて困るので。
// _ なら使わなくても警告吐かれない。 let _ = std::fs::remove_file("memo.txt");
Mac でビルド成果物を実行する
恥ずかしながら僕にはわからなかった。 ビルド成果物があるディレクトリに移動して・・・👇
./hello_world
./ がない場合、コマンドなしの結果になる。
実行ファイルを実行するには ./ が必要。
標準ライブラリで最も一般的なスマートポインタ
Box<T>ヒープ上にメモリを確保するスマートポインタRc<T>多重所有を可能にする参照カウント型スマートポインタRef<T>RefMut<T>コンパイル時ではなく実行時に借用規則を実施する型であるRefCellを通してアクセスされるスマートポインタ
Rc::clone の使い所
あんまりよくわからないけど、グラフデータなどで複数のノードから一つのノードを参照するような構造を作る際に使える。通常のBox(再帰は可能)などで実現しようとすると所有権の問題でコンパイルできない。それを解決するのにDeepClone しちゃうと性能の問題が発生するし、全く別のインスタンスを参照することになってしまう。
そんな場合に Rc::new で唯一のノードを作成し、それを参照する複数のノードは唯一のノードを引数に Rc::clone することで、同一インスタンスへの参照を持つことができる。
Interior mutability pattern(インテリアミュータビリティパターン)
std::cell::RefCell の使い所。 Mock オブジェクトを使って試験したい場合の例がわかりやすい。
Rc と RefCell の合わせ技
もうなんだかわからん。
MPSC
multiple producer, single consumer の略。
連番のVecを作る
fn main() { let min = 8; let max = 13; let vec: Vec<u8> = (min..max).collect(); println!("{:?}", vec); // [8, 9, 10, 11, 12] }
スレッド間で値を安全に共有するためのAtomic Reference Counting, Arc.
引用:
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
等価比較する
/// derive で PartialEq を指定すると、プロパティ全てを等価比較する挙動となる。 #[derive(PartialEq, Debug)] struct A { x: u8, y: u8, } /// 独自の実装が必要であれば derive で PartialEq を指定せず impl で fn eq を実装する。 #[derive(Debug)] struct B { id: u8, foo: u8, } impl PartialEq for B { /// id が同じならば等価とみなす fn eq(&self, other: &Self) -> bool { self.id == other.id } } fn main() { let a1 = A { x: 1, y: 2 }; let a2 = A { x: 1, y: 2 }; let a3 = A { x: 3, y: 3 }; assert_eq!(a1, a2); assert_ne!(a1, a3); let b1 = B { id: 1, foo: 1 }; let b2 = B { id: 1, foo: 2 }; let b3 = B { id: 3, foo: 1 }; assert_eq!(b1, b2); assert_ne!(b1, b3); }
詳しくは👉 Eq in std::cmp - Rust
impl 内の fn の引数で self: Box<Self> になってるのなに
いやぁそろそろわけわからなくなってきましたが、説明にはこうありました。
メソッドの最初のパラメータとして、self、&self、&mut selfではなく、self: Box
となっていることに注意してください。この構文は、その型を持つBoxに対してメソッドが呼び出されたときのみ有効であることを意味します。この構文は、Box の所有権を取得し、古い状態を無効にして、Postの状態値が新しい状態に変換できるようにします。
Box に格納している場合のみ呼び出し可能な関数を定義する際に使うのだろうか。 とても使い所が難しい気がする。
参考👇
Implementing an Object-Oriented Design Pattern - The Rust Programming Language
パターンがマッチし続ける限りwhileループを実行することができる while let
if letと似た構造のwhile let条件付きループは、パターンがマッチし続ける限りwhileループを実行することができます。リスト18-2の例は、ベクターをスタックとして使用し、ベクター内の値をプッシュされたのと逆の順序で表示するwhile letループを示しています。
let mut stack = Vec::new(); stack.push(1); stack.push(2); stack.push(3); while let Some(top) = stack.pop() { println!("{}", top); }
引用元👇
All the Places Patterns Can Be Used - The Rust Programming Language
イテレータの中身をindexとともに取得したい時は enumerate() を使う
let v = vec!['a', 'b', 'c']; for (index, value) in v.iter().enumerate() { println!("{} is at index {}", value, index); }
参考👇
All the Places Patterns Can Be Used - The Rust Programming Language
Vec<u32>.iter().map(|n| *n++) のように n は dereference が必要?
iter_into() を使うと dereference は不要?
collect() を変数に格納せずに型指定する
assert_eq!( vec![1, 2, 3].iter().map(|n| *n * 2).collect::<Vec<u8>>(), &[2, 4, 6] );
お手軽にコピーしたいときは
#[derive(Copy, Clone)]
テストで println! を標準出力する
以下でテストを実行することで標準出力されるようになる。
cargo test -- --nocapture
Rust の Vec をインデックス付きでループする方法
引用元:Rust の Vec をインデックス付きでループする方法 参考にさせて頂きます。ありがとうございます。
let a = ['a', 'b', 'c']; for (i, val) in a.iter().enumerate() { println!("{}: {}", i, val); }
👇 (0_i32..) のような書き方もできるのか〜びっくり。
let a = ['a', 'b', 'c']; for (i, val) in (0_i32..).zip(a.iter()) { println!("{}: {}", i, val); }
勉強になります。
JS でいうところの array.some
some ではなく any でした。
let a = ['a', 'b', 'c']; let result = a.any(|item| item == 'a');
Rust の補完が効かない問題
以下と rust-analyzer があれば良さそう。
rustup component add rust-src rustup component add rust-analysis rustup component add rls
フロントエンドで Selenium を使って TDD した話
本記事は Qiita の「テスト駆動開発 Advent Calendar 2020」の12月12日の記事です。
長くなってしまったので、目次だけでも読んでいってください!
経緯とモチベーション
2019年夏ころ~2020年夏ころまでの間、とあるSIerのWebアプリケーション開発プロジェクトにてフロントエンドを担当することになりました。
そこで、以下のお達しを受けました。
- ウォーターフォールです
- 1年で200画面、前半フェーズと後半フェーズに分けて作ります
- SPA です
- RESTful API です
- テストでは画面のエビデンスを残すこと
- フロントエンドは Unit Test 書かなくて良い
Unit Test 書きたいです。 200画面も手でテストしたくありません。 だって、 SPA で RESTful API。かなり複雑化する気がします。
あと、意地でも TDD やってみたいんです。 少し前に TDD の本を読んだので完璧にできます。 アンチパターン? 手段が目的? とにかくやってみます。
「TDDで構築後に、エビデンスを撮るために画面からもテストする」みたいなことは絶対にしたくない。
こんなモチベーションですみません。
使用した技術や環境
環境は以下。
- Windows10
- サポート対象ブラウザは Edge のみ
- Visual Studio Code
技術は以下を使用しました。 Selenium 以外は初めて触ります。
やってみた所感
開発初期はとにかくスピードが出ません
開発初期には書いてたコードの半分以上がテストのユーティリティのコードでした。 TDDには程遠い状況で、むしろ逆TDDでした。プロダクトコードを先に書き、それをパスするテストコードを苦労して書き、Greenを維持したままテストコードをリファクタリングする感じです。
テストコードのリファクタリングが功を奏した
開発初期のテストコードのリファクタリングが功を奏して、開発から3か月くらいたったころには大分開発スピードが出るようになり、Seleniumで悩むことも少なくなりました。
開発から6か月たったころには、TDD ができていました。稀に、新しいUIコンポーネントを使うシーンなどで逆TDDをしました。
プロダクトコードのメンテナビリティ
以下の観点で、メンテナビリティを高めることができたかと思います。
- リファクタリングが容易
- 障害対応が容易
最も外側からテストするので、リファクタリングは容易です。 ただ、リファクタリングを一生懸命やる人、やらない人がいるので、ムラがあったかと思います・・・。
障害が発生した場合は、問題となる操作やデータでのテストを追加し、プロダクトコードを改善します。リグレッションテストも素早く終わるので、障害対応は容易でした。
私個人の感想としては、とてもメンテナンスしやすかったです。
メンテナビリティと言えば可読性ですが、このテストによって直接的に可読性が高まるということはありませんでした。リファクタリングがしやすいので、副次的に可読性が高まるということはあり得るかと思います。(そうなったつもり)
テストの実行に時間がかかる
アンチパターンですね。
1画面に掛かるテストの実行時間は、完成したテストで平均で3分くらいです。
特にバリデーションのテストの実行に時間がかかるので、テストコードをコメントアウトしたりして、実行時間を短くします。そういうことをすると、リグレッションを起こすことが稀~にありました。さすがアンチパターン!
また、TDDで流すテストスイートは、現在構築中の画面のもののみか、影響が出そうな画面のみです。また、全画面のテストを一気に流すことはできません。全画面やろうと思うと開発中期で100画面ほどあって1画面3分でも・・・5時間ですか。さすがアンチパターン!
これだけ実行時間が長いと、一歩がデカくなります。さすがアンチパターン!
そして、私が編み出した技が・・・
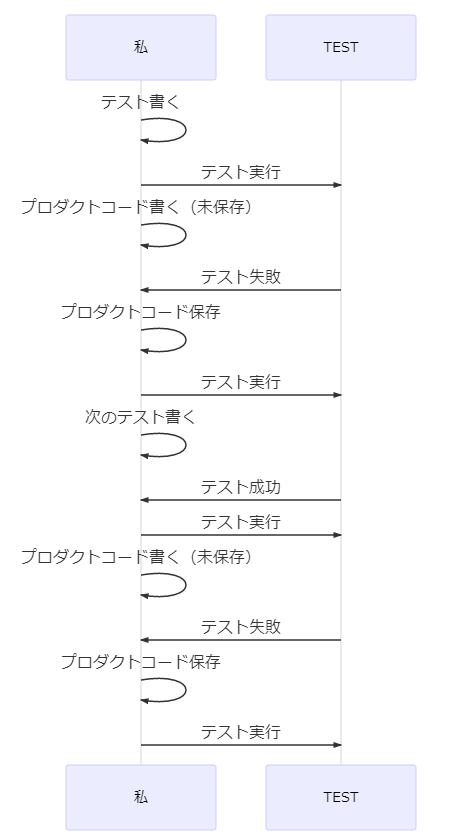
調子が良いときはこの技がキマります。常に私のターンです。 テストの実行完了を待つ必要はありませんね。
たまにコケます。
結合テスト以降の障害
結合テスト以降は我々の手を離れ、テストされていきます。 数件障害が上がったものの、品質の良さは評価されました。
数件上がった障害は、開発初期に構築した複雑な画面で、テストが不足していること、新しい技術 ( Vue ) に慣れていなかったことが要因です。
また、開発初期の画面はテストコードが否メンテナブルで、修正は少しだけ手間でした。それでも、2~3時間で再現テスト実装/修正/テスト&リグレッションテスト&エビ撮り/リリースができるので、やはり自動化は正義だなと思いました。
テストの粒度
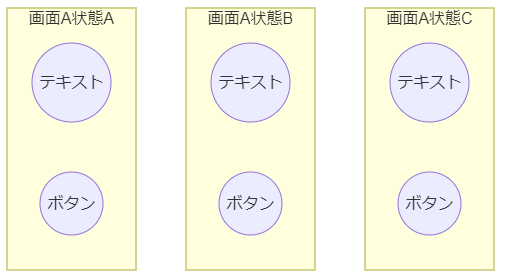
以下のような2つの観点での粒度についてです。
- 画面の状態の粒度
- 画面の状態一つに対するチェックの粒度
例えば下記の図で言うと、1つの画面に対し3つの状態をテストし、チェックはそれぞれ「テキスト」と「ボタン」に対して行います。(図が適当すぎるごめんなさい)
画面の状態の粒度
実装する人によりますが、必要な分だけテストします。不安なところは実施し、不要になったら削ることもしました。多いと時間がかかります。さすが・・・
画面によっては、テストのテンプレートとなるクラスを用意し、それを使うことで実装者による粒度のムラが発生しないようにしたりもしました。まぁ、そんなことができる画面はそもそも共通コンポーネントで作ってたりしますね・・・。
画面の状態一つに対するチェックの粒度
充実した粒度で、メンバー間で統一することができました。 ユーティリティを充実させたことで、例えば以下のようなチェックを簡単に行えました。
- テキストボックスのチェック
- 表示されていること
- 活性状態であること
- Readonlyでないこと
- 値が空であること
こう見るとまぁ・・・オーバーキルかも・・・。 ですが、必要なチェックではあります。 大量のチェックを素早く正確に行えるのは有用でしょう。素早く・・・(白目)
ドメイン知識を得られるか?
TDDの利点として、ドメイン知識を得るきっかけになり得るというものがあるそうです。今回のテスト対象はUIです。UIのドメイン知識とはなんでしょう・・・。例えば以下のようなものでしょうか。
コンポーネントについての知識
コンポーネントについての知識は得にくいと感じました。特定のコンポーネントを意識したテストを書けば、そのコンポーネントの知識を得ることは可能かと思います。とは言え、神クラスを部分的にテストしているような感覚があるかもしれません・・・。
画面のデザインや要素の構成
デザインをテストするのは、SnapShotとかでできるんでしたっけ。データとか、ブラウザのウィンドウの大きさとかで左右されそうで怖かったのでやりませんでした。それに、ここで頑張らなくてもリリースまでの間に多くの人の目に触れてフィードバックが来るでしょうから、それで良いようにも思いました。
要素の構成は、やろうと思えばできるでしょうが、重要ではないですし変わりやすいところです。テストに組み込むべきではないでしょう。
画面の要素の細かな挙動
これについての知識は多く得られます。当然ですかね。
APIのリクエスト/レスポンス
何らかの操作をした際正しいリクエストを投げているのか、そのレスポンスを受けて画面がどう変わるのかを細かくテストしました。
この活動によって、API の仕様についてかなり細かく確認し、考察し、実装前や結合テスト前でも多くの問題を見つけ修正することに繋がったと思います。それがテストのおかげなのかというと、100%そうではないですが。
画面遷移
当然チェックします。 話はそれますが、「戻る・進む」の試験も実装しました。これはバグが出やすいんですよね。
所感まとめ
感覚でしかないのですが5点満点で表現すると以下の感覚です。 テストコードやテスト環境などの改善を繰り返していましたので、開発初期(最初の3か月くらい)よりも開発後期のほうが良くなっていて、その差が大きいので別で評価しています。
テストの粒度は品質と相関関係にあるわけではないですが、後期ですごく多くなったので特徴的な性質として載せています。

開発初期に悪かったことをどうやって乗り越えたか
ここからは具体的かつ技術的な話になります。
開発初期には「開発速度」と「テストコードのメンテナビリティ」の面が非常に悪かったです。とにかくそれを試行錯誤しながら改善しました。最終的な我々の「やり方」を記載します。
Seleniumをラッピング
- 仮想テキストボックスクラス
- 仮想ボタンクラス
- etc
上記のような画面要素操作クラスを作り、Seleniumを直接触らずともブラウザを操作可能としました。 こんな感じで使えるので、直観的に要素を操作する処理が書けます。
const idTextbox = new VirtualTextbox({id:'#id', name:'IDテキストボックス'}); await idTextbox.setValue('hori-chan'); await idTextbox.clear(); await idTextbox.isVisible(); await idTextbox.isEnable();
チェック処理を共通化
画面の要素のチェック処理や、画面のURL、APIのURL / query / body などのチェック全てを共通化しました。
例えば以下のように書くと、idTextboxCheckDefiner.defineTests(); でテキストボックスのテストを展開します。
// jest です describe('画面表示時のテスト', () => { beforeAll(async () => { // 画面表示処理 }); const idTextbox = new VirtualTextbox({id:'#textbox-id', name:'IDテキストボックス'}); const idTextboxChecks = TextboxChecks.create({ element: idTextbox, isVisible: true, isEnable: true, isReadonly: false, value: '', }); const loginButton = new VirtualButton({id:'#button-login', name:'ログインボタン'}); const loginButtonChecks = ButtonChecks.create({ element: loginButton, isVisible: true, isEnable: false, label: 'ログイン', }); // テキストボックスとログインボタンのテストを展開 new CheckDefiner().add(idTextboxChecks, loginButtonChecks).defineChecks(); });
上記で展開されるテストはこんな感じになります。
- 画面表示時のチェック
- IDテキストボックスのチェック
- 表示されていること
- 活性状態であること
- Readonlyでないこと
- 値が空であること
- ログインボタンのチェック
- 表示されていること
- 非活性状態であること
- テキストが'ログイン'であること
- IDテキストボックスのチェック
上記で言うTextboxChecksクラスやButtonChecksクラスは、それぞれ jest のdescribeメソッドにて「IDテキストボックスのチェック」や「ログインボタンのチェック」を展開します。
それぞれのChecksクラスは、内部的に以下のようなクラスを持っており・・・
- VisibilityCheck
- EnableCheck
- ReadonlyCheck
- ValueCheck
それぞれのCheckクラスが、jestのtestメソッドを実行し、その中でexpect(await virtualElement.isVisible()).toBeTruthy()みたいなことをしています。
1画面のテストにつき定義するクラスの構成を統一
.spec.ts ファイルにはテストの概要部分を定義し、細かな部分は以下のクラスのインスタンスに処理を移譲しました。
- XxxViewCheckDefiners
- .spec.ts から参照される
- 「画面表示時」や「ログインボタン押下時」などの単位で、画面のURLや各要素やAPIなどの Check をまとめて生成して返却するメソッドを持つ。
- Check は XxxViewChecks から取得し、デフォルトのチェック内容から変更がある場合は、その項目のみ再指定する。
- XxxViewChecks
- XxxViewCheckDefiners から参照される。
- 画面のURLや各要素やAPIなどの Check を一つ一つ定義し、デフォルトのチェック内容を設定する。
- XxxViewOperations
- .spec.ts から参照される
- テスト対象画面への遷移操作や、画面の要素への値の入力、次の画面へ遷移するボタンの操作を行うメソッドを定義する。
- XxxViewParts
こんな関係です。
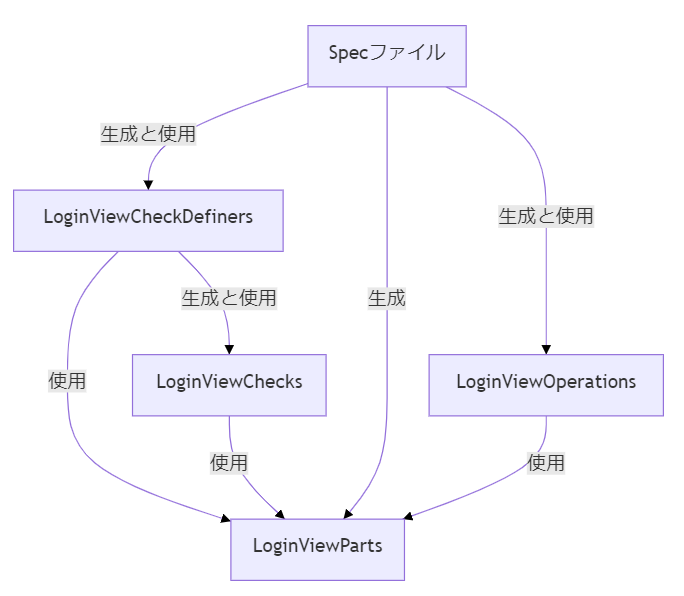
specファイルはこんな感じになります。
describe('Login画面', ()=> { describe('画面表示時', ()=> { const parts = LoginViewParts.create(); const definers = LoginViewCheckDefiners.create(parts); const operations = LoginViewOperations.create(parts); operations.goToMyPage(); definers.whenViewed.defineTests(); }); describe('ログイン成功時', ()=> { const parts = LoginViewParts.createForSuccess(); const definers = LoginViewCheckDefiners.create(parts); const operations = LoginViewOperations.create(parts); operations.goToMyPage().login(); definers.whenLoginSuccessful.defineTests(); }); describe('ログイン失敗時', ()=> { const parts = LoginViewParts.createForFailure(); const definers = LoginViewCheckDefiners.create(parts); const operations = LoginViewOperations.create(parts); operations.goToMyPage().login({nextUrl: parts.URL_LOGIN}); definers.whenLoginFailure.defineTests(); }); });
parts生成時にユーザー情報を指定したりして、操作で入力する値やチェック定義における内容が少し変わります。変えすぎると破滅します。
エビデンスは Markdown で出力
画面のエビデンスを撮れと言われていました。そこで、エビデンスを Markdown で出力する仕組みを作りました。あと、上の項まででSpecファイルの可読性は高まりましたが仕様が読み取りにくかったので、エビデンスを充実させてその代わりとすることも目的でした。
ただし、テストコードにはなるべくエビデンスを扱う処理を書きたくありません。そこで、以下の施策をとりました。
- Jest の describe や test メソッドに渡してるテスト名みたいなのを取得してエビデンスに使用する
- 画面キャプチャは operations などで何かしらの操作を行う前後に自動で撮る(キャプチャ要否を boolean で指定するくらいは我慢した)
- specファイルごとにmdファイルを出力する
- 目次を作る
- 失敗したテストには赤字で警告を表示する
- etc
jest のテスト名みたいなのは、jest からは上手く取得することができなかったので、結局 jest の関数を wrap した関数($describeとか$testとか)を作って使用することとし、そこでテスト名を受け取り収集するなどの工夫をしました。
これにより、画面の仕様がエビデンスに出力されることとなりました。
json-server のテストデータがデリケートで困る
画面を動かす都合上どうしてもデータに依存したテストになってしまいます。しかし、データは開発が進むにつれてどんどん追加・変更され、最悪既存のテストが動かなくなります。 そこで、json-server がデータとして読み込むjsonファイルから動的にデータを取得し、テストの期待値として使用することとしました。
動的にデータを取得しテストの期待値として使用する
その代わり、テストコード側でのデータ取得時に、そのデータがそのテストでの目的を果たせるデータであるかどうかをチェックします。チェックした結果、テストデータとして不適切なものであれば、エラーをスローしてテストを失敗させます。
「テストコードにおいて期待値はべた書きすべき」 というのが通説かと思います。 ですが我々のテストにおいては、データの取得経路が全く異なるので品質を担保できると判断しました。
開発初期に悪かったことをどうやって乗り越えたかまとめ
もっと色々とやったことはありますが、特に上記の対策でうまくいきました。
以下にこのやり方をして良かったこと・悪かったことを記載します。
良かったこと
- specファイルを可読性が高い状態に保てた
- エビデンスの統一感が良い感じ、そして見やすい
- チェック内容や結果の文言が統一できた
- エビデンスのフォーマットが統一できた
- チェックの粒度を統一できた
- Seleniumのコツを実装者が覚えなくて良い
- TDDできるほどにテストの定義が容易
悪かったこと
- テストユーティリティの作成に工数がかかる(1年のうち3か月くらい使ったかも)
- テスト実行に時間が掛かる
- 実装者によってメンテナビリティにムラが出る
頑張ったんですけどね、メンテナビリティが高いコードを書くことを強制するというのは、難しいです。
総まとめ:大成功
大成功でした!やって良かったと思ってます。アンチパターンと言われている割には有用だったと思いました。長い実行時間に次にやるべきことを考えたり、1歩が大きくてもなんとかなります。今後メンテナンスでどう活かされるのかも体験しておきたかったですが、私は別のプロジェクトに移ってしまいました。残念。
そして、成功でしたがもうやらないと思います。
やっぱり遅いです。サクサクやれたほうが楽しいと思います。画面のエビデンスを細かく撮る必要がある場合はやるかもです。
長文駄文にお付き合いいただきありがとうございました。
おまけ
json-server で色々やった話
テスト用のMockサーバーとして json-server を使用していました。 json-server は、jsonファイルでデータを用意しておき、シンプルにそのデータのCRUDをRESTfulに実行するのが基本動作ですが、設定を変更して色々と挙動を変更しました。
例えば以下のような細工をしていました。
受けたリクエストをファイルに吐き出す
テストの中でファイルに吐き出したリクエスト参照し、想定通りのリクエストを投げているのかをチェック可能にしました。
好きなタイミングで好きなレスポンスを返す
jest から json-server に「次のレスポンスはこのステータスでこのBODYを返してください」とリクエストを投げておき、次にブラウザからリクエストを行った際にそのレスポンスを返却させるようにしました。HTTPステータスはテストしにくい部分ですが、とてもやりやすかったです。
テスト対象の画面にたどり着くまでにいくつも画面を経由する場合の書き方
結構これで、困る人が多いのではないかな~と思ってます。
いくつも画面を経由する場合、その途中の画面の仕様が変わったりすると、後続の画面まで影響が出かねません。
そこで、上述の「1画面のテストにつき定義するクラスの構成を統一」で紹介したOperationクラスを活用します。
前の画面の Parts と Operation のインスタンスをテスト対象画面の Operation インスタンスが保持し、テスト対象画面の Operation の goToMyPage() メソッド(次画面へ遷移する処理)の中で、前の画面の Operation の goToMyPage() メソッドを呼ぶようにしました。そうすることで、画面遷移処理が DRY となりメンテナンスしやすくなります。
まぁ、それだけです。
ナンプレSPAを vue + TypeScript で作った話 〜フロントエンドにクリーンアーキテクチャを適用する〜
- ナンプレSPA(number place infinity)とは
- ※注意
- 始め方
- ルール
- 遊び方
- 使った技術
- デプロイ環境
- 作った経緯
- アーキテクチャ
- 課題
- 学んだこと・経験したこと
- 11/30の発表で言わなかったこと
※本記事は2020/11/30のゆるWeb札幌にてナンプレについて発表させていただいた際の資料をブログ記事に落としたものです。
ナンプレSPA(number place infinity)とは
ブラウザで動作するナンプレのアプリです。 静的なSPAとなっており、ページ取得時以外でサーバーとの通信は行いません。

※注意
- 選んだ盤のサイズが大きい場合、高い負荷がかかり問題の生成に時間がかかる場合があります。
- 30秒ほど待っても問題が生成されない場合はブラウザのタブを閉じるか、戻るボタンやリロードボタンを押下し、初期画面に戻りやり直してください。
- 負荷が掛かるせいでブラウザの他のタブに影響がないと言い切れないため、作業中のタブがある場合は作業を完了するなどしてから問題の生成を行ってください。
始め方

- まるい数値のボタンで盤の大きさを決める
- STARTボタンを押す
9x9や10x10など大きめの問題は、生成に時間がかかります。 生成中はフリーズしているように見えます。20秒くらいは待ってください。 待ちきれない場合はブラウザの当該タブを閉じて最初からお試しください。
ルール
1~nの数値を縦・横・太枠の四角いエリアの中で重複しないように埋めていき、全てのマスを埋められたら成功です。
遊び方
カーソルの動かし方

- マスをタップまたはクリック
- タッチムーブ(画面上のどこでもタッチしたまま指を動かすことでカーソルを動かせます)
- キーボードの矢印キー
数値の入力
- 画面右下の半月状のコントローラの数値をタップ
- キーボードの数値キー
数値の削除
- 画面右下の半月状のコントローラの×をタップ
- キーボードのBackSpaceキー
使った技術

デプロイ環境

完全に静的で通信を行うことのないブラウザアプリになってます。
作った経緯
→ナンプレを解くライブラリを作ってみよう!
- 2019/10
- ゆるゆると作り始める
- 2019/12
- 問題を解くロジックが完成 →白紙から解いたら問題を生成できるのでは?
- 2020/1
- 問題を生成するロジックが完成 →UIも作ってみるか〜
- 2020/2
- UI作って公開
アーキテクチャ
- クリーンアーキテクチャを意識している
- CoreとApplicationは純粋なTypeScriptのクラスで構成されている(アノテーションのみTSyringeに依存している)
- データを管理する部分はDIで実装
- Viewは表示と入力受付に徹する
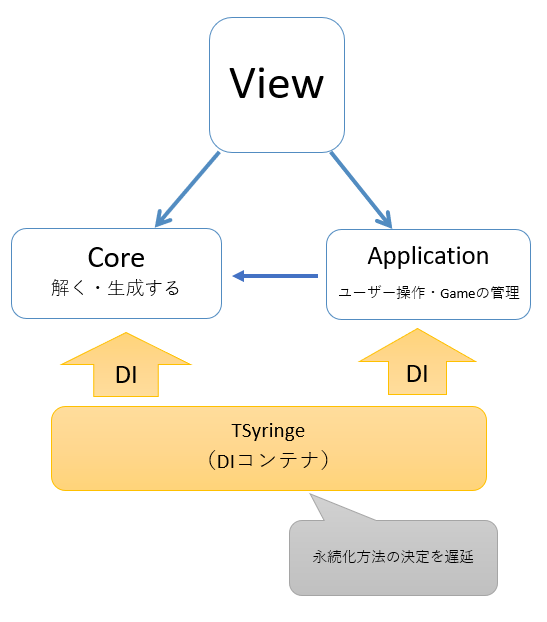
Core/Application/View 分離のメリット
詳しくは書籍「クリーンアーキテクチャ」参照のこと!
私の感じたメリット
- 重要かつ複雑なCoreとApplicaitonを扱いやすく作れた
- Viewの都合による変更が入り込まない
- UIを無視し単体で試験
- 永続化処理部分をMock化して開発
- 決定の遅延

課題
- ゲームはできるが楽しさややり込み要素が足りない
- もうちょい素敵なコントローラーにしたい
- CoreとApplicationとViewのプロジェクトを別々にしたい
- 問題生成処理性能改善
- レガシーコードからの脱却
- テストを書いて無理やり動かしたクソコードと複雑な設計
- 理解不足のDDDプラクティス
学んだこと・経験したこと
- 複雑なロジックにテストを書いて立ち向かう
- Core部分が複雑でテストがないと完成させられなかった
- フロントエンドもクリーンアーキテクチャは有用
- 決定の遅延 / 開発速度UP / テスト容易性UP
- フロントエンドに DDDのプラクティス は有用か?
11/30の発表で言わなかったこと
追加で言いたいことを言いまくります。
背景画像はアイヌ文様
背景画像はアイヌ文様のフリー素材のモレウというサイトから拝借しています。 モレウ様ありがとうございます!
ちょっとしたことで使いにくさが解消された
選択中のセルをハイライトする際、初めはセルの背景色を薄いピンク色で点滅させていました。 スタイルでこんなことできるのかーという気持ちで採用したピンク点滅ですですが、これを辞めたことでグッと使いやすくなったと思いました。 ピンク点滅だった頃は、遊んでいると疲れてしまい、楽しむ気になれないほどでした。 これをやめてから、自分自身もしっかり楽しめるようになりました。
おすすめナンプレアプリ
ナンプレアプリを作っておいてなんですが、以下のiPhoneアプリが好きです。おすすめです。

ナンプレアプリを自分で作るまでは中級までしか解けませんでしたが、アプリを作ってからは超上級の「極」まで解けるようになりました。もちろん自分で。
クリーンアーキテクチャやDDDの「プラクティス」って何?
あえて「プラクティス」と言いました。 クリーンアーキテクチャやDDD「風」に作っており、厳密には違うかもです。 ですが、巷で「軽量DDD」と呼ばれている設計のテクニックが存在しており、ここではそれらを「プラクティス」と表現しました。
クリーンアーキテクチャやDDDやそれらのプラクティスを正しく理解しているかと言われると、僕は全く自信はないです。僕はDDDを経験したことがありません。ま、一人で開発してるってことは、自分がドメインエキスパートなんですが。 いつかは本当にDDDをしてみたいですね。
自分が「良い」と思えば良いんです。このアプリはある程度「クリーン」です。 とは言え、現状に満足しているわけではありません。自己研鑽あるのみです。
DIコンテナのTSyringeについて
実は使用したのはこのアプリでのみです。 実務で使ったことはなく、今後使うこともないように思います。
というのも、このTSyringeはアノテーションでDIする際に、コンストラクタがpublicでなくてはならず、僕の設計方針に合わないからです。 あと、単純に、あまり使い勝手が良くないような。
そして、過去に携わった業務においてTSyringeの使用を拒否された(当時現場でフロントエンド全般の学習コストが問題視されていた)際、自分でコンテナを作りDI(アノテーションは使いませんでしたが)するようにしたところ、とてもシンプルで良いものができたので、それからコンテナを自作するようになりました。 自作コンテナと言ってもただのグローバル変数のようなものなんですけどね。
僕の設計方針:static creation
クラスのほとんど全てを、private constructorとし、そのクラスに定義するpublic static create() などの生成メソッドを使用してインスタンスを取得するようにしています。 同じクラスでも生成するシチュエーションによって生成方法や生成したインスタンスの使用目的が異なる場合が多々あります。 これに対応する名前を付けた静的ファクトリーメソッドを使用することで、可読性が高く、少しだけ柔軟な設計が可能となります。
このちょっとした柔軟性の高まりで後々救われることがあります。 やらない理由はないです。必ずそうします。
このテクニックは「static creation」と呼ばれているそうです。 2019年秋に仙台で行われたTDDBCに参加しt_wadaさんにレビューいただいた際にそう呼ばれておりました。間違いないです。
このテクニックは、例えばこんな感じで使っています。
class User< TFor extends 'for-create' | 'for-reconstruct', TId extends string | undefined = TFor extends 'for-create' ? undefined : string > { public static create(name: string): User<'for-create'> { return new User(undefined, name); } public static reconstruct(id: string, name: string): User<'for-reconstruct'> { return new User(id, name); } private constructor(public readonly id: TId, public readonly name: string) {} } const userForCreate = User.create('John'); const userForUpdate = User.reconstruct('123', 'Mike');
新規登録時に作るUserはidを持っていませんが、DBやAPIで取得したUserはidを必ず持っています。 同じクラスのインスタンスですが、異なる性質を表現できます。 いちいちID持ってるかどうかの判定をしたくありませんよね。 無い場合は絶対に無い、有る場合は絶対に有るんですから。 (idをクラス化するケースもありますけどまぁそれはおいておいて)